
robots.txtはクロール管理であり、秘密の保護やnoindexではない
Robots Exclusion Protocolは、協力するクローラーに取得してよいURLを伝える仕組みです。命令の強制、認証、検索結果からの確実な削除、サーバー負荷対策の保証を行うものではありません。
使う目的
不要な検索・絞り込みURL、重複生成URL、レンダリングに不要な資源などのクロールを管理します。大量URLでは、URL設計、canonical、リンク、サイトマップ、サーバー性能も同時に見直します。
検索結果から外す目的
HTMLはrobots metaのnoindex、PDFなどはX-Robots-Tagを使い、クローラーがその指示を取得できるようrobots.txtでは遮断しません。反映には再クロールが必要です。
機密情報を守る目的
認証、認可、ネットワーク制限、保存場所の分離で保護します。robots.txtに管理画面やバックアップのパスを書くと、存在を公開することになります。
緊急削除の目的
公開停止、認証、noindex、削除ツールなど目的に合う方法を組み合わせます。Disallowだけでは、外部リンクからURLが発見され検索結果にURLだけ残る可能性があります。
個人情報、顧客データ、バックアップ、設定ファイル、未公開資料をrobots.txtで保護しないでください。該当URLが匿名利用者から取得できるなら、まずアクセスを止め、漏えい範囲とログを確認します。
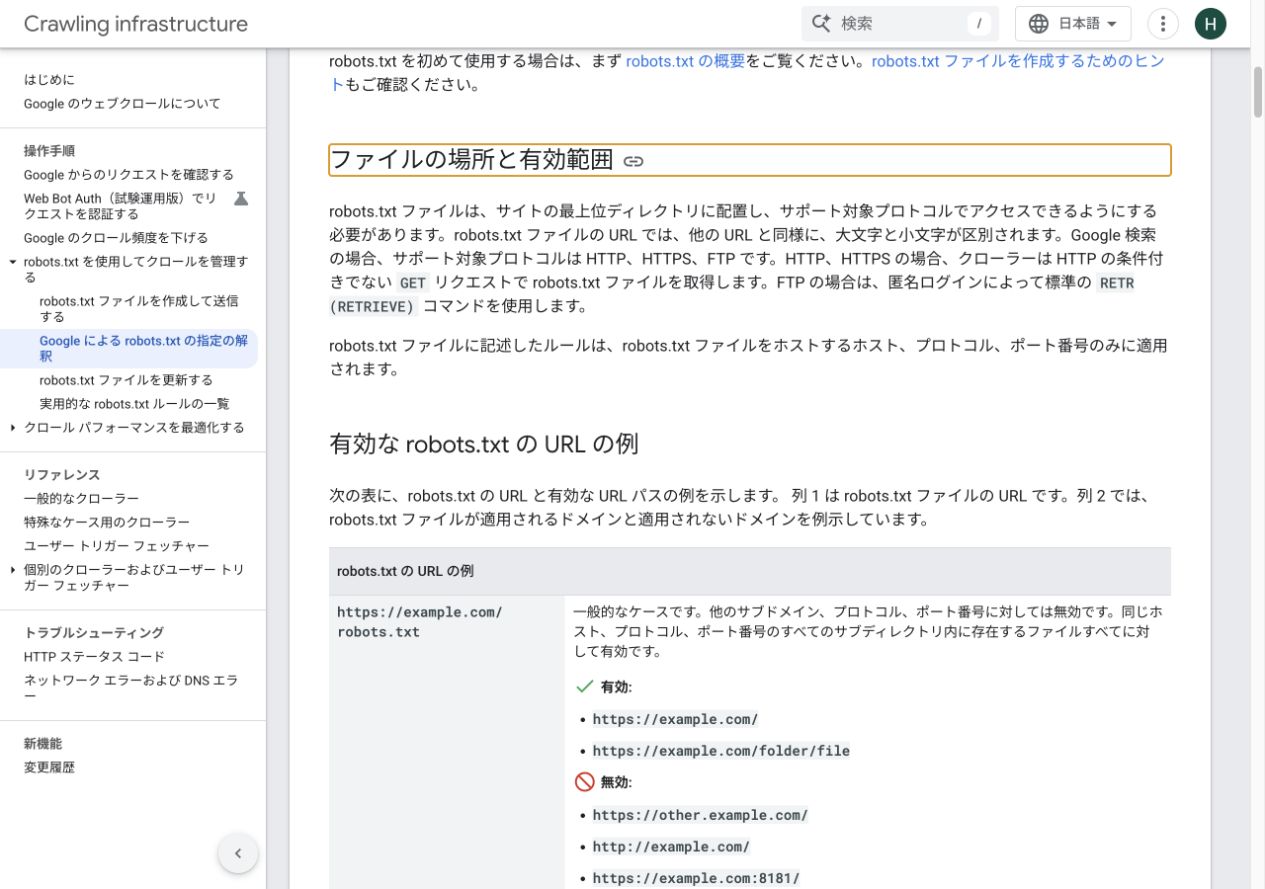
適用範囲はプロトコル・ホスト・ポートの組み合わせで決まる
robots.txtは小文字の /robots.txt として各サービスのルートに置きます。https://example.com/robots.txt は同じHTTPS、ホスト、標準ポートのパスへ適用され、HTTP、別サブドメイン、非標準ポートへは自動適用されません。
表は横にスクロールできます。
| robots.txtのURL | 適用される例 | 適用されない例 | 必要な対応 |
|---|---|---|---|
| https://example.com/robots.txt | https://example.com/products/1 | http://example.com/、https://www.example.com/ | HTTPとwwwを公開するなら各オリジンも確認 |
| https://shop.example.com/robots.txt | https://shop.example.com/cart | https://example.com/、https://cdn.example.com/ | サブドメインごとに所有者と規則を管理 |
| https://example.com:8181/robots.txt | https://example.com:8181/admin/ | https://example.com/(443) | 外部公開が必要か先に判断 |
| https://example.com/help/robots.txt | 有効な配置ではない | サイト全体 | ルートの/robots.txtへ移す |
URLフラグメントはサーバーへ送信されない
robots.txtの一致対象はパスと、実装が扱うクエリ部分です。#section のようなフラグメントはHTTP要求に含まれないため、robots.txtで区別できません。大文字小文字、末尾スラッシュ、エンコード、クエリを実URLで確認します。
User-agentのグループと最も具体的なパス規則を判定する
標準の中心はUser-agent、Allow、Disallowです。Sitemapは主要検索エンジンが対応する追加レコードです。クローラー固有の拡張は、対象クローラーの公式仕様を確認します。
User-agent
規則を適用するクローラーの製品トークンを指定します。* は、より具体的に一致するグループがないクローラーに適用されます。ユーザーエージェント文字列の一部を推測せず公式一覧で確認します。
User-agent: *
Disallow
一致するURLの取得を許可しない規則です。値が空なら制限しません。Disallow: / はサイト全体へ一致するため、公開環境では重大な変更として扱います。
Disallow: /search/
Allow
広いDisallow内で、より具体的なURLを許可します。単純に後の行が勝つのではなく、最も長く一致する規則を使い、同じ長さならAllowが選ばれます。
Allow: /search/help/
Sitemap
サイトマップまたはサイトマップインデックスの完全URLを記載します。User-agentグループの規則ではありません。サイトマップ自体の200応答と掲載URLも別に検証します。
Sitemap: https://example.com/sitemap.xml
一致判定の例
Disallow: /catalog/ と Allow: /catalog/help/ がある場合、/catalog/item/1 は不許可、/catalog/help/size はより具体的なAllowで許可されます。パスは大文字小文字を区別するため、/Catalog/ は別に確認します。
危険な指定は公開前の停止条件として扱う
構文が正しくても目的が誤っていれば障害になります。URL数、重要ページ、レンダリング資源、インデックス制御、セキュリティ、クローラー対応の観点で差分を確認します。
公開環境のDisallow: /
サイト全体のクロールを止めます。ステージング用ファイルの本番反映、環境変数の誤り、CDNキャッシュを確認し、公開パイプラインに検知を入れます。
Disallowとnoindexの併用
クロールを止めると、ページ内のnoindexやレスポンスのX-Robots-Tagを取得できません。検索結果から外す必要があるURLは、noindexを読める状態にします。
CSS・JavaScript・画像の一括遮断
重要なレンダリング資源を遮断すると、検索エンジンがページを正しく理解できない場合があります。資源の役割と参照元を確認し、不要な生成物だけに限定します。
機密パスの列挙
robots.txtは公開されます。/backup/、/private/、管理用パスを書いても不正クライアントを止められません。認証とネットワーク制御を使います。
広すぎるワイルドカード
* は0文字以上、$ はURL末尾を表す実装があります。/*.pdf はクエリ付きPDFにも一致し得ますが、/*.pdf$ は末尾が.pdfのURLへ限定されます。対象エンジンで確認します。
未対応のCrawl-delay
Googleはrobots.txtのcrawl-delayをサポートしていません。他のクローラーの対応は各公式資料で確認し、負荷問題はレート制御、キャッシュ、性能改善、正規のクロール設定でも対処します。
404・403をブロックとして使う
Googleは429以外の4xxを、クロール制限のないrobots.txtとして扱います。認証をかけたrobots.txtでサイトを守ろうとせず、公開ファイルを200で安定配信します。
リダイレクトチェーンとHTML応答
標準は少なくとも5回のリダイレクト追跡を定めますが、直接200で返す方が安全です。ログイン画面、WAFページ、404 HTML、言語転送が返らないか確認します。
robots.txtのHTTP応答は規則と同じ重要度で監視する
同じファイル内容でも、状態コード、Content-Type、文字コード、リダイレクト、キャッシュ、障害で解釈が変わります。Google固有の扱いとRFC 9309の基準を分けて記録します。
| 応答 | 主な影響 | 運用確認 |
|---|---|---|
| 2xx | 取得した規則を解析 | 200、text/plain、UTF-8、本文、キャッシュを確認 |
| 3xx | クローラーが一定回数追跡 | 同じ目的の最終/robots.txtへ一段で送るか直接配信 |
| 404などの4xx | Googleは429以外を制限なしとして扱う | 意図した未設置か、配信事故かを区別 |
| 429・5xx・通信障害 | 取得停止、キャッシュ利用、再試行など影響 | アラート、直近正常版、復旧時間、サーバーログを確認 |
キャッシュにより修正が即時反映されない
Googleは通常robots.txtを最大24時間程度キャッシュし、取得できない状況では長く使う場合があります。Search Consoleのrobots.txtレポートで取得時刻と版を確認し、必要な場合だけ再クロールをリクエストします。
変更前にURL判定表を作り、最小規則を配信する
大量の規則を書き始める前に、許可・不許可にしたい代表URL、クローラー、目的、代替制御を表にします。まずステージング相当のURL集合で判定し、公開環境の現行版と差分を取ります。
- 1
対象オリジンを列挙する
HTTP・HTTPS、www、サブドメイン、CDN、画像ホスト、非標準ポートを列挙し、各/robots.txtの所有者と配信方法を確認します。
- 2
URLを許可・不許可・別制御へ分類する
重要ページ、検索・絞り込み、管理画面、API、CSS・JS、画像、PDF、サイトマップ、存在しないURLを含めます。秘密は認証、noindexはクロール許可へ分けます。
- 3
最小のグループと規則を書く
重複グループと推測したクローラー名を避け、最も狭いDisallowと必要なAllowだけにします。コメントには理由と変更票番号を書き、機密情報を書きません。
- 4
配信層とキャッシュを固定する
アプリ、Webサーバー、CDNのどこが正規ファイルを持つか決めます。環境別ファイルが本番へ混入しないよう生成・デプロイ・キャッシュ無効化を自動化します。
- 5
限定公開から監視を開始する
可能なら低リスクな規則から公開し、取得ログ、重要URL、クロール、エラーを観測します。全体ブロックや広いパターンは追加承認を必要にします。
最小構成の例
User-agent: *
Disallow: /search/
Allow: /search/help/
Sitemap: https://example.com/sitemap.xmlこの例は /search/ 配下を一般に遮断し、/search/help/ だけ許可します。実サイトへコピーせず、検索結果ページが重要コンテンツでないか、内部リンクやcanonical、サイトマップと矛盾しないか確認してください。
ファイル取得とURL判定を別々に検証する
ファイルが200で開くだけでは、目的のURLに正しい規則が適用されるか分かりません。各オリジンの応答と、クローラー・URLごとの判定表を保存します。
- 1
ブラウザとcurlで配信を確認する
正確な https://ホスト/robots.txt を開き、curl -i で状態、Content-Type、文字コード、Location、Cache-Control、本文を確認します。CDNとオリジンの差も確認します。
- 2
構文とグループを解析する
UTF-8、改行、User-agent、空のDisallow、グループ境界、重複規則、未知のフィールド、ファイルサイズを確認します。規則より前に置かれたAllow・Disallowは使いません。
- 3
URL判定表を全件実行する
各User-agentについて、トップ、重要下層、許可例、不許可例、大文字小文字、末尾スラッシュ、クエリ、エンコード、CSS・JS・画像、サイトマップを判定します。
- 4
Search Consoleで取得版を確認する
robots.txtレポートで最新取得、エラー、警告、過去の版を確認します。特定URLのブロック判定はURL検査ツール、開発時の大量検査はGoogleの公開robots.txtライブラリなどを使います。
- 5
公開後のログと検索信号を監視する
robots.txt取得、重要URLのGooglebotアクセス、4xx・5xx、クロール統計、インデックス、レンダリングを変更前と比較します。不正クローラー対策はWAFやレート制御で別に観測します。
確認コマンド例
応答と本文: curl -i https://example.com/robots.txt | リダイレクト追跡: curl -IL --max-redirs 5 https://example.com/robots.txt | 本番URLと認証情報を外部テスターへ送る場合は、機密性と利用条件を確認します。
公開と復旧はファイル・キャッシュ・検索制御を一緒に管理する
変更票に現行版、変更版、公開時刻、担当、停止条件、復旧版を添付します。robots.txtだけ戻しても、CDNキャッシュや同時変更したnoindex・サイトマップが残る場合があります。
- 1
公開前の正常版を保存する
本文、応答ヘッダー、ハッシュ、取得時刻、URL判定表、Search Consoleの取得版を保存し、ワンクリックで戻せる配信版を用意します。
- 2
停止条件を監視する
重要URLの不許可、全体ブロック、robots.txtの4xx・5xx、HTML応答、想定外ホストへの転送、レンダリング資源遮断を検知したら拡大を止めます。
- 3
正規配信層で前版へ戻す
別の層へ応急規則を追加せず、正規ファイルを前版へ戻します。対象CDNキャッシュを限定して無効化し、各オリジンから再取得します。
- 4
競合する制御も復元する
同時に変更したnoindex、X-Robots-Tag、canonical、サイトマップ、内部リンクがあれば、承認済みの同じ版へ戻します。
- 5
取得とURL判定を再確認する
curl、判定表、Search Console、ログで復旧を確認します。検索エンジン側のキャッシュが更新されるまで影響を監視し、原因と再発防止を記録します。
robots.txt変更の完了チェック
ファイルの構文だけでなく、適用範囲、URL判定、配信、検索制御、復旧を同じチェックシートに残します。
目的と範囲
- クロール管理、noindex、機密保護を区別
- プロトコル、ホスト、サブドメイン、ポート一覧
- 対象クローラーの公式製品トークン
- URL許可・不許可・別制御の判定表
規則
- User-agentグループ、最長一致、同長Allow
- 大文字小文字、末尾、クエリ、エンコード
- CSS・JS・画像・PDF・サイトマップ
- 全体ブロック、機密パス、未対応拡張なし
配信と検証
- /robots.txt、200、text/plain、UTF-8
- リダイレクト、WAF、認証、CDNキャッシュ
- 全URL判定表と重要操作のレンダリング
- Search Console取得版、URL検査、ログ
公開と復旧
- 現行版、変更版、ハッシュ、承認、公開時刻
- 停止条件、監視、担当、連絡先
- 前版復元と限定キャッシュ無効化
- noindex・canonical・サイトマップとの整合
根拠にした一次資料・標準資料
標準と検索エンジン固有実装を区別しています。利用するクローラー、CDN、CMSの現行公式資料も照合してください。
robots.txtでよくある質問
robots.txtでDisallowすれば検索結果から消えますか?
保証されません。外部リンクなどからURLが発見されると、本文を取得せずURLだけ表示される場合があります。検索結果から外す目的ではnoindexまたはX-Robots-Tagを使い、その指示を取得できるようクロールを許可します。
管理画面をDisallowすれば安全ですか?
安全にはなりません。robots.txtは公開され、従わないクライアントもいます。管理画面は認証、認可、ネットワーク制限、多要素認証、監査ログで保護します。
Allowは後に書けばDisallowより優先されますか?
行の順番だけでは決まりません。RFC 9309とGoogleでは最も具体的、つまり一致するパスが長い規則を使い、同じ長さでAllowとDisallowが競合すればAllowを使います。
Crawl-delayでGooglebotを遅くできますか?
Googleはrobots.txtのcrawl-delayをサポートしていません。負荷の原因をログで確認し、キャッシュ、性能、URL空間、正規のクロール頻度設定、必要なレート制御を検討します。
Search Consoleの古いrobots.txtテスターはどこですか?
現行のrobots.txtレポートで取得版、エラー・警告、履歴を確認し、特定URLのブロック判定にはURL検査ツールを使います。開発時の自動検査にはGoogle公開ライブラリなどを利用できます。
クロール・インデックス管理の関連ガイド
robots.txtは適用範囲とURL判定表で管理する
オリジンごとに正規ファイルを200で配信し、User-agentと最長一致をURL単位で確認します。機密保護とnoindexを分離し、公開後は取得版、重要URL、ログ、復旧版を継続管理してください。
この記事の編集・検証方針
Finite Field 編集部
RFC 9309、Googleのrobots.txt実装、Search Consoleレポート、robots meta仕様を照合し、標準、検索エンジン固有挙動、セキュリティ対策を区別して編集しています。
複数サイト・大量URLのクロールを管理する方へ
robots.txt設計とクロール監査を相談する
サブドメインやCDNが多い、検索・絞り込みURLが大量にある、重要URLを誤って遮断した場合は、オリジン一覧、現行ファイル、URL判定表、ログ、Search Consoleの取得版を準備してください。
クロール管理を相談する構成と運用条件を確認したうえで対応可否をご案内します。特定クローラーの遵守、検索順位、再クロール時期、インデックス反映、事故の完全防止を保証するものではありません。